Kafka & Zookeeper 基础知识
kafka简介
Kafka最早诞生是为了解决Linkedin的data pipeline问题。
数据处理最重要的是有一个完整的数据流,而不是数据模型
日志充当了一个缓存作用,使得读写可以异步
Data which is collected in batch is naturally processed in batch. When data is collected continuously, it is naturally processed continuously.
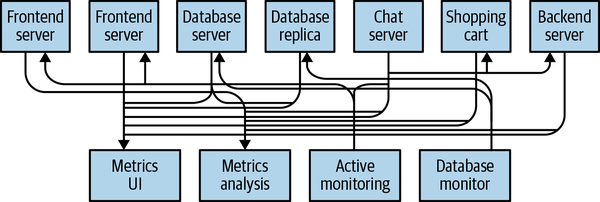
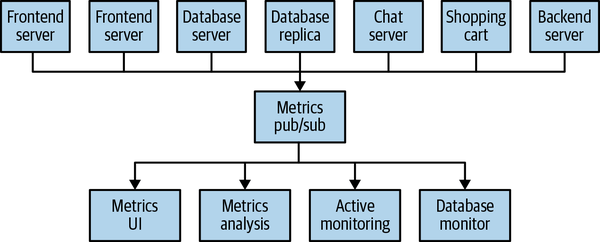
使用Kafka的优势是显而易见的:不需要再去做各种各样的routing和wiring,就能将metrics通过统一的平台进行统计、分析和分发。
Schema
Kafka的消息都是字节数组,但是也是有结构定义的。
Stream
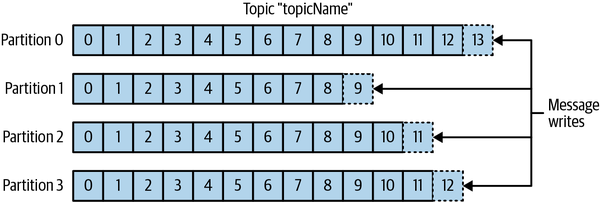
Stream指的是同一个Topic的消息,和Partition的数量无关。同一个消息可以有多个Partition,也可以分散在多个节点上,提升性能和冗余度。
Producer Consumer
Producer指的就是消息的生产者,通常会平均地向每个Partition分摊消息。但也有特殊情况,生产者只会向特定的Partition发送消息。
Consumer读取消息,订阅一个或多个Topic,按顺序读取消息。
Offset
Consumer和Kafka都保留了一个Offset,一个不完全单调递增的int,后来的消息offset更大。每个partition的offset都被保存着,这样Consumer暂停接受消息后,就可以resume。
Consumer group
一个或多个Consumer共同消费同一个topic。Consumer group确保每个partition只会被一个member消费。这也被称为Ownership。
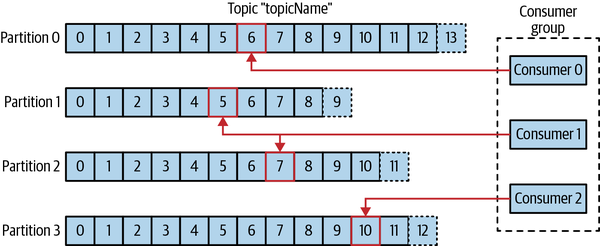
如果一个member fail了,那个partition会被重新分配到剩余的members中。
Brokers and Clusters
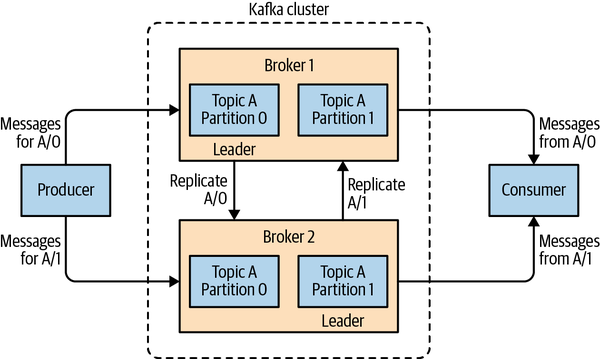
Broker从producer接受消息,设置offset,然后写入存储。消息有主从同步。
消息有存储限制和时长限制,超出了就会被删掉。
MirrorMaker
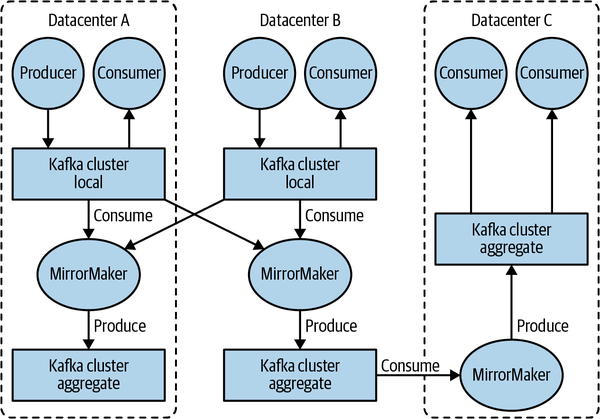
灾备的MirrorMaker本身就是一个consumer和producer,consume其他集群的消息然后produce到本地集群。
优势
多Producer,多Consumer,本地留存。
高性能,高可用
生态
Zookeeper
消息队列的挑战
消息延迟
P比Q先发送消息,但Q的消息先到
处理速度
T~ps~ + T~s~ + T~pr~ 时延 = 发送+传输+接受
时钟对齐
处理器时钟有可能不准,或者未对齐
消息没收到,有可能是三种情况的任意一种
主从结构
主节点crash
需要备用Master,新的Master能够从crash时的状态恢复。此时,我们不能指望从crash掉的master那里读取恢复时的context,所以需要把数据存在别的地方,就是zookeeper里。
split-brain 一个系统中两个或多个部分独立地完成工作,比如master实际在工作,但由于网络故障,集群被划分为了两半。
Worker crash
重新分配调度给Worker的任务。任务可能执行了一半,也可能已经完成但无法汇报结果。如果有Side effect,那么还需要清理状态。
通讯故障
锁不能解决问题
具体功能
Master election
拥有master才具有分配任务的功能,所以必须能够选举
Crash detection
Master能够检测到worker crash
Group membership management
Master能够得知哪些节点能够执行任务
Metadata management
主节点和从节点都能够存储分配和执行状态
Zookeeper 并不是 Byzantine fault tolerant的,因为这会大大增加复杂性和开销。
Fischer, Lynch, and Patterson FLP
异步通信,并且会故障的进程,并没有办法对哪怕1bit的信息达成共识。
Impossibility of Distributed Consensus with One Faulty Process, 1983
ZNode tree
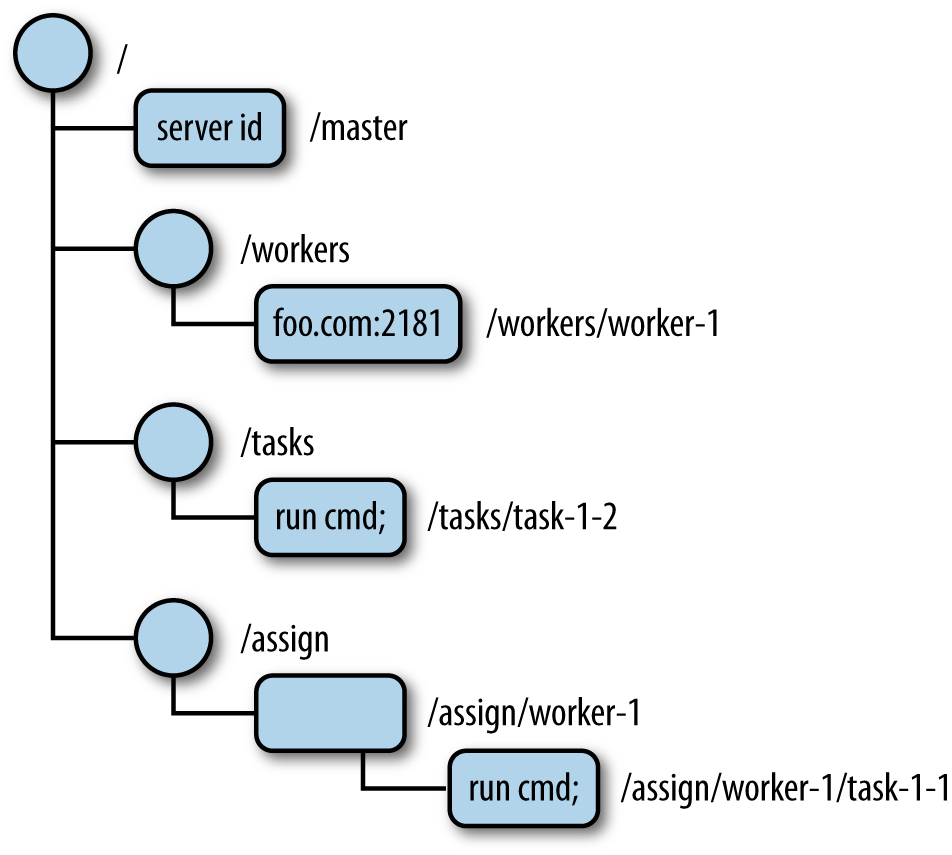
Znode的所有信息都被存在一棵树里,包括Master,Workers,Tasks和Assign。
如果有数据缺失,就说明有地方出错了。比如Master这里的值是空,就说明需要进行Leader election。
事物原子性
Zookeeper有API可以对数据进行读写,但读或者写操作都是原子性的。
Polling vs Notification
Polling:
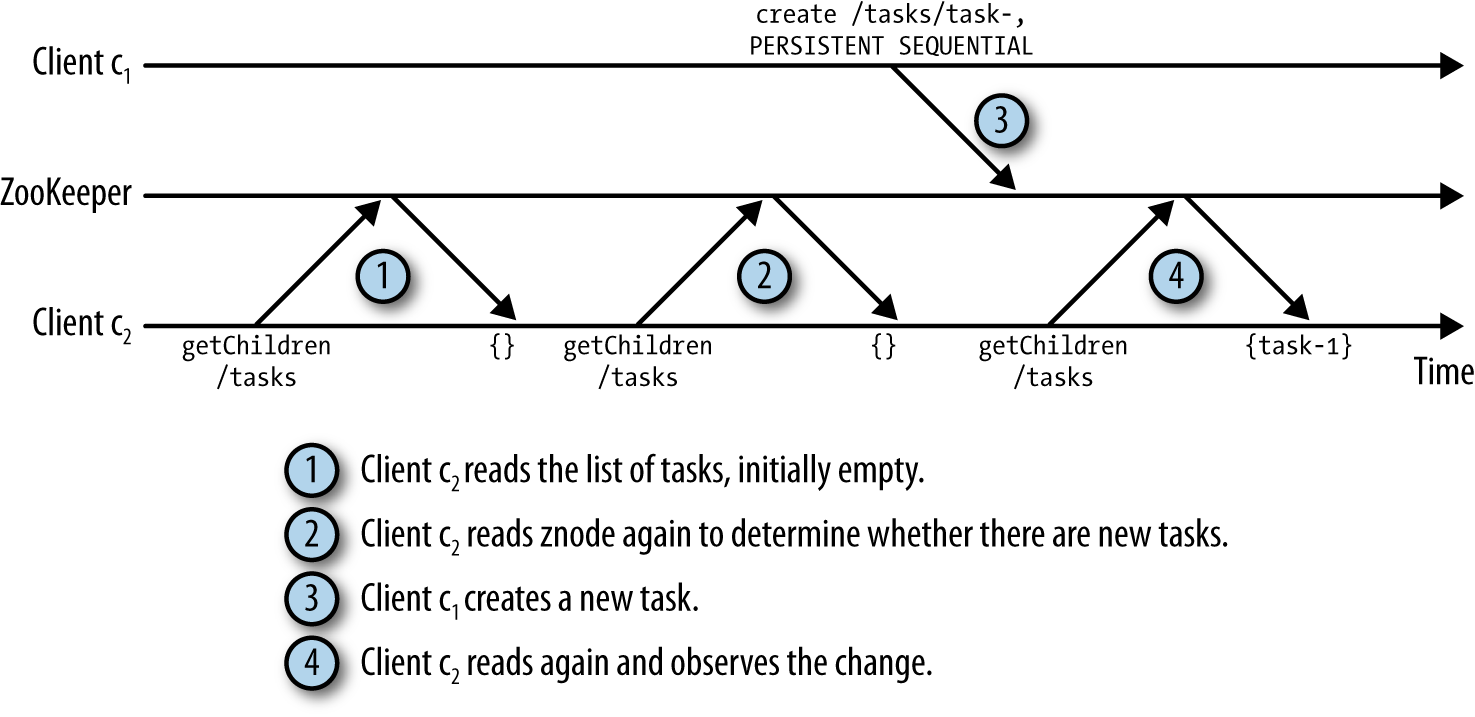
可以看到,操作2是不必要的。
Notification:
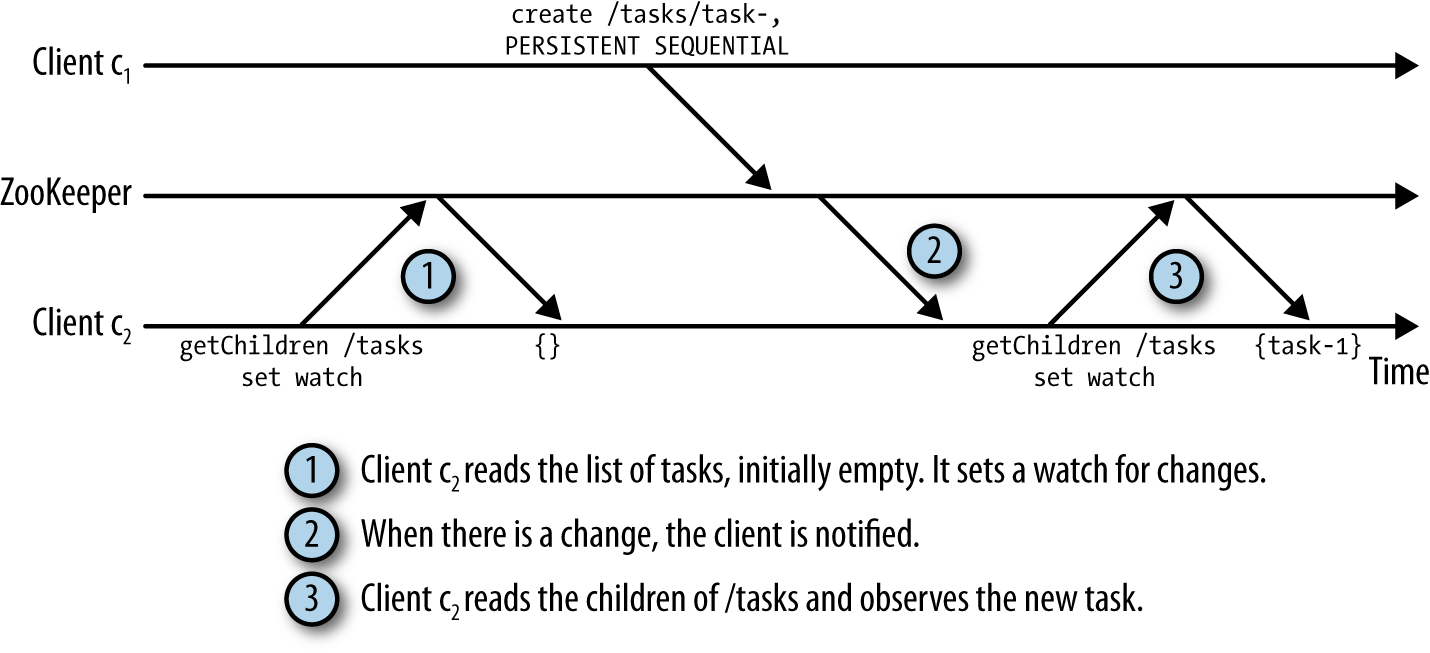
Version Number
每个Znode都有一个版本号
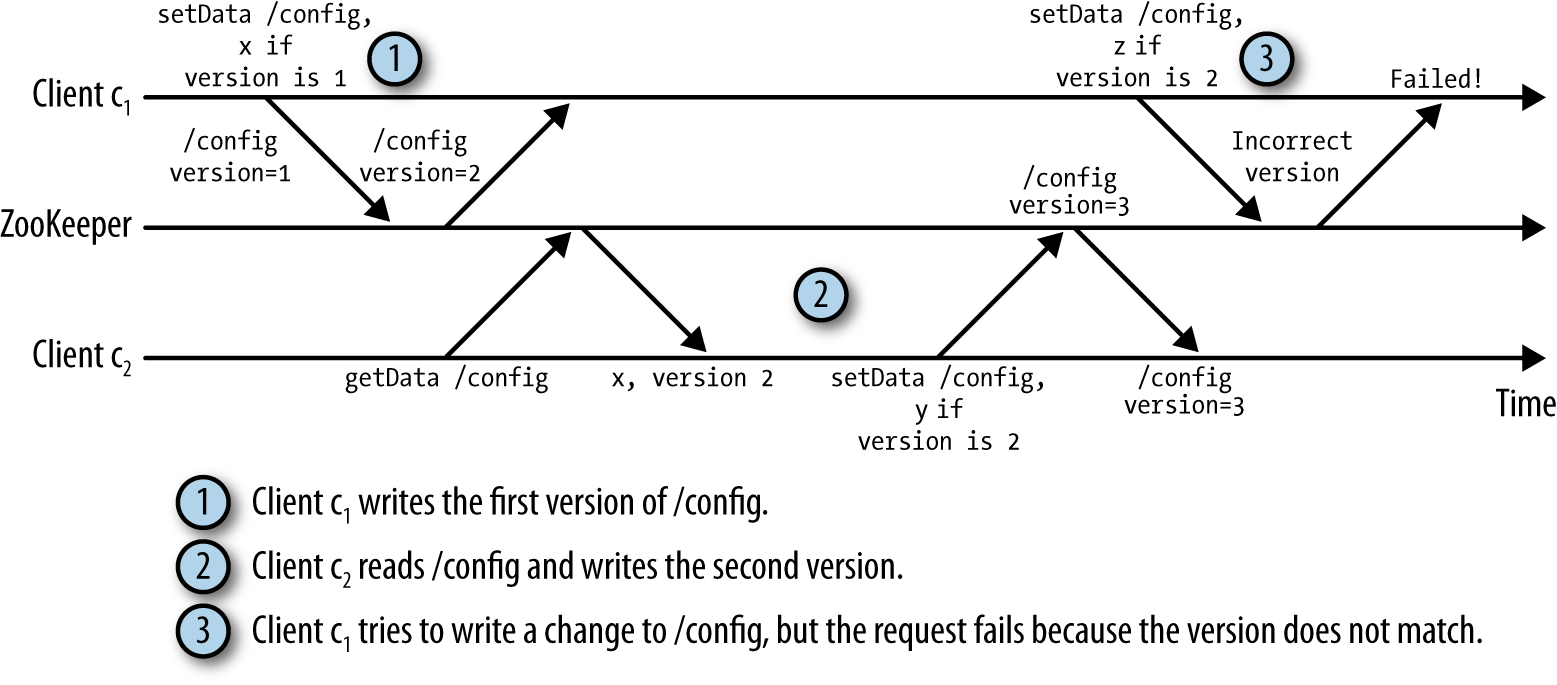
与Application 交互
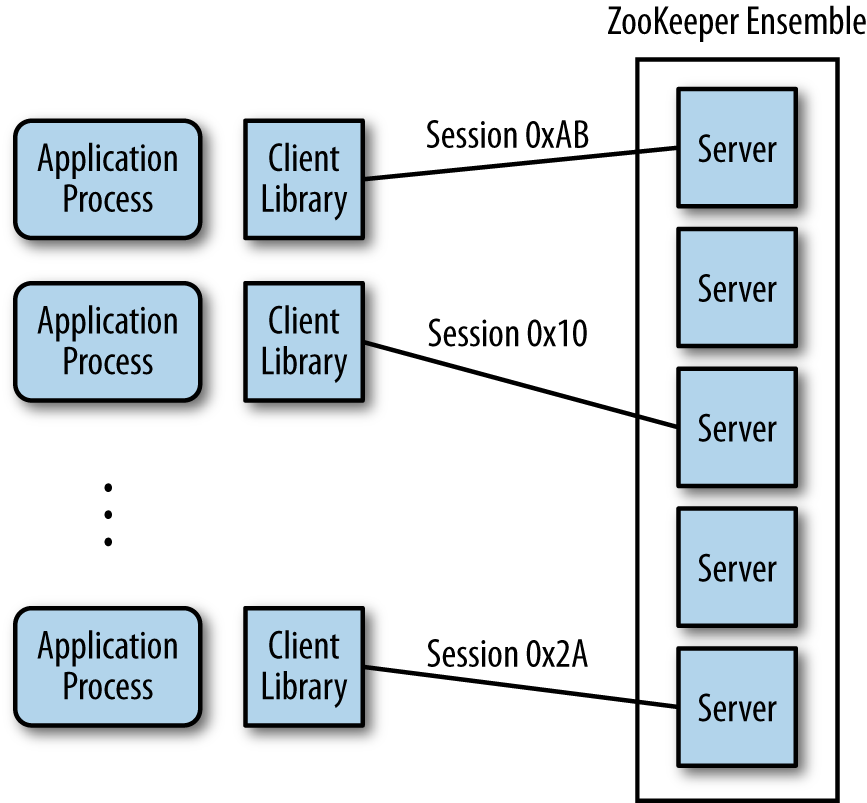
Standalone mode:一个Zookeeper server
Quorum mode: 多个servers,states replicate
多数server确认状态被复制,才能成功更新状态,避免split-brain
Leader Election
Looking state,Follower state 和 Leader state三种状态
发现Leader 挂掉,马上进入looking state,然后互相给每个resemble 里的server发消息,是一个tuple包含自己的serverID(sID)和上一个请求的transaction ID(zxID)。然后对比,选出最新处理请求的当选leader
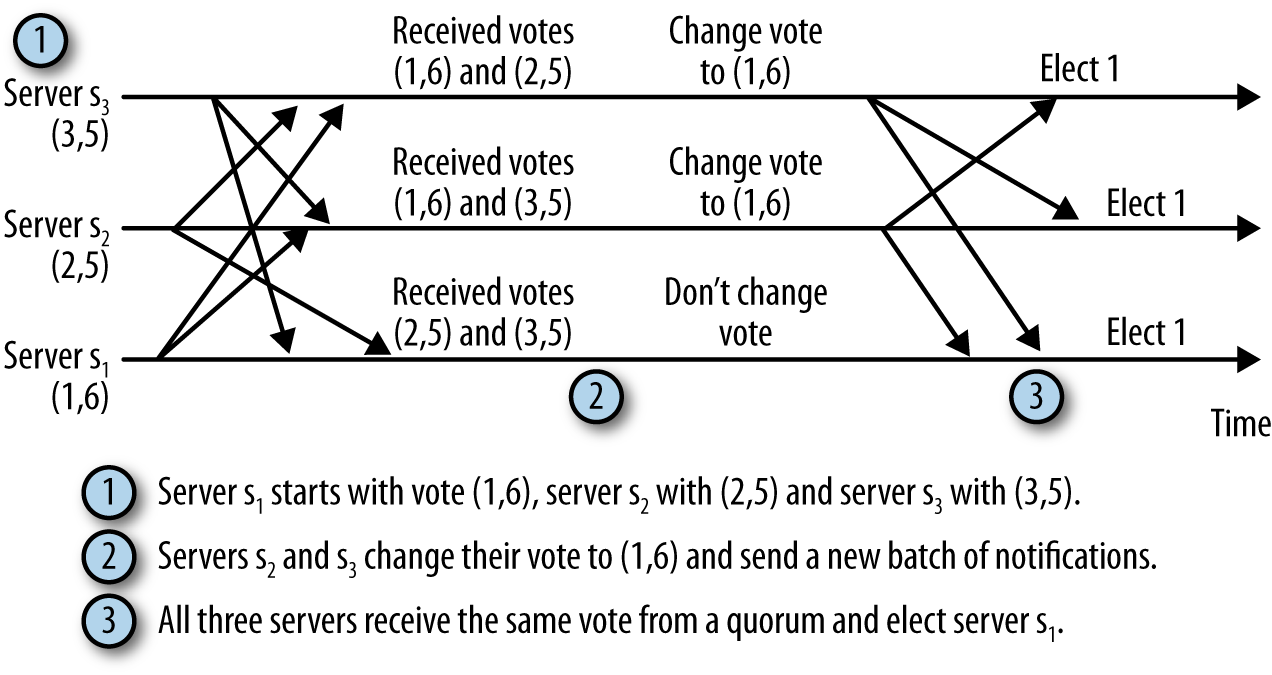
但是这样做是建立在选举时网络条件很好的情况下。
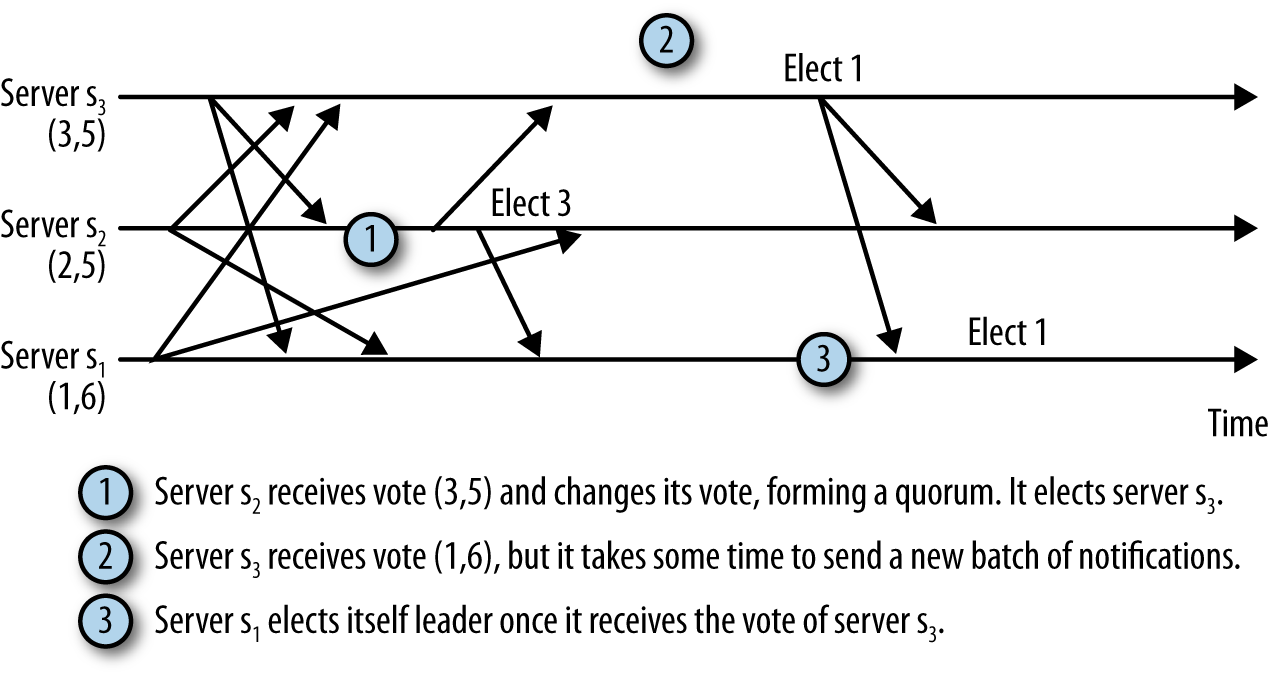
如果网络有延迟,就会出现这样的情况。因此,可以加上一个超时,设定等待的最长时间。Fast Election就设置了200ms
Zab: the ZooKeeper Atomic Broadcast protocol
- 首先,Leader会向所有Follower发送一个Proposal 信息
- Follower向Leader 发送 ACK
- Leader 向Follower 发送 Commit
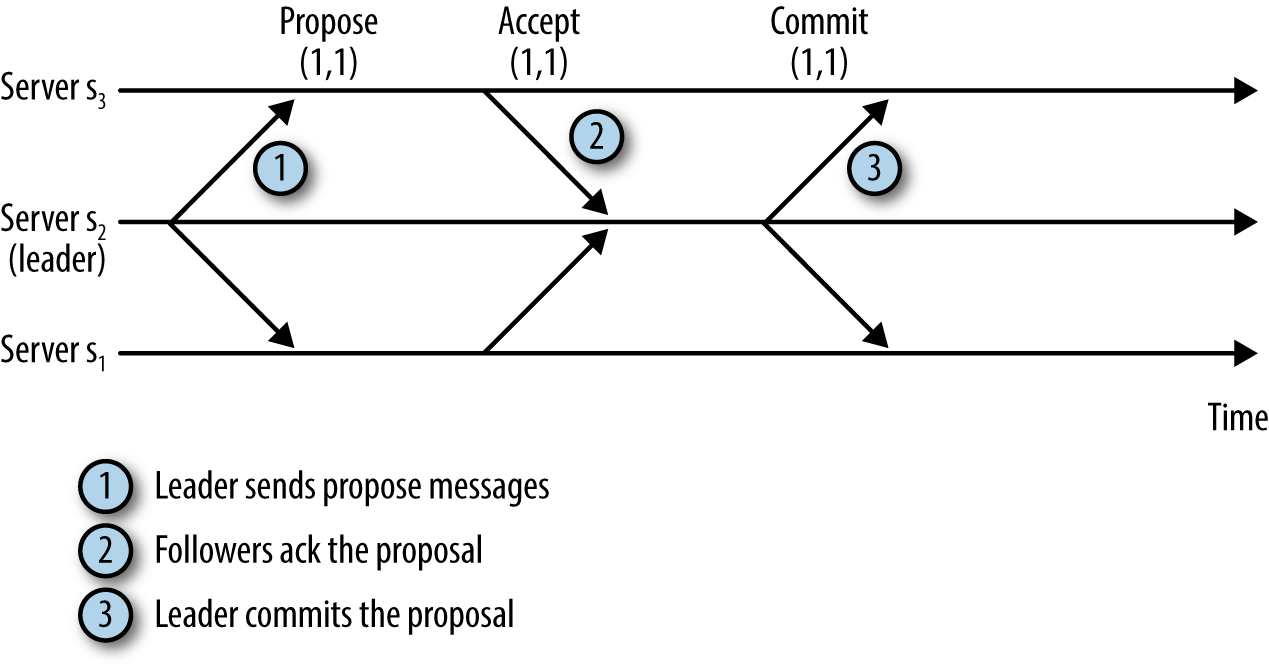
这样做能确保事务的处理顺序,并且不遗漏事务。
Epoch:代表Leader的term,每次leader election都会增加epoch,每次transaction都会包含epoch
DIFF:转换Epoch时,如果相差不多,Leader会发送Follower缺失的transaction。
SNAP:相差很大,Leader会发送全量的snapshot
Observers
不参与投票,不参与proposal
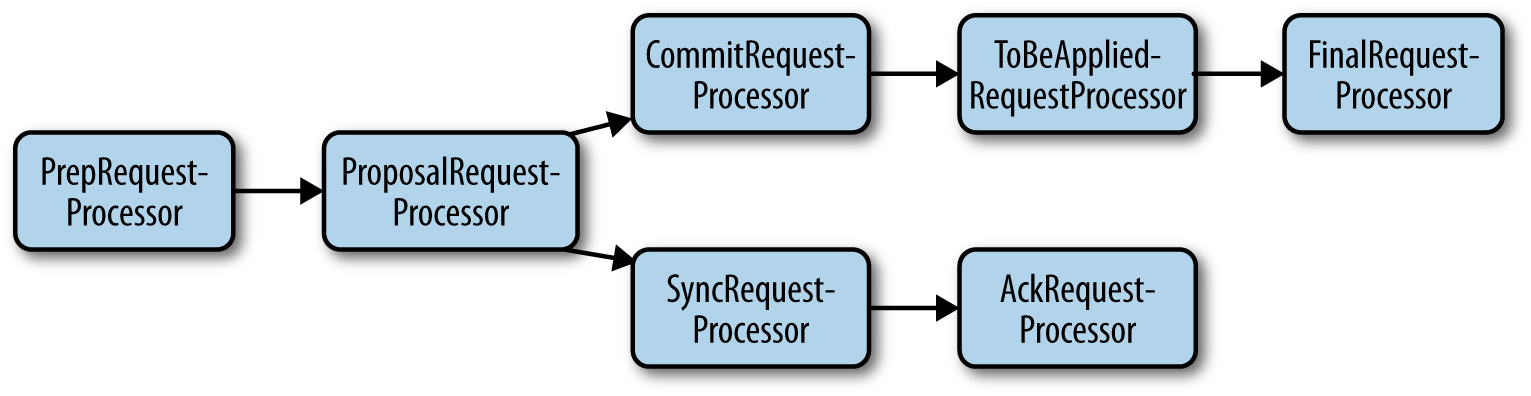
Master在处理完Proposal后,会同时处理Commit以及持久化到本地
回到Kafka,kafka的broker就是在zookeeper中以/brokers/ids的形式注册的。
由于ephemeral node的特性,当broker失联了,session断开,它的节点就会被zookeeper自动移除。
Controller
broker+ partition leader election,每个cluster只会同时有一个controller。
KRaft
2019年开始的项目
现有问题:
- Metadata同步写入ZooKeeper,分发给broker却是异步。因此存在broker,controller,zookeeper三者状态不一致的情况
- 当controller重启时,需要重新从zookeeper读全量的状态数据,非常慢。
- Ownership不明确,同样的数据有些是controller改的,有些是broker改的,有些是zookeeper改的
- Zookeeper本身也是一个分布式系统
解决方法:
KRaft,将controller分为 active controller 和follower controllers,active controller负责处理broker事务。
Controller nodes自己leader election,原本存储在zookeeper的数据存在一个log中。
KIP-595: A Raft Protocol for the Metadata Quorum - Apache Kafka - Apache Software Foundation
KIP-631: The Quorum-based Kafka Controller - Apache Kafka - Apache Software Foundation
Partition Replicas
每个Topic 可以有多个Partition,而每个Partition可以有多个replica。
Replica也分主从,主负责处理client request,从复制消息并且作为备份。
KIP-392之后,follower partition也可以处理client request。
KIP-392: Allow consumers to fetch from closest replica - Apache Kafka - Apache Software Foundation
Requests
Apache Kafka, Purgatory, and Hierarchical Timing Wheels | Confluent
Request type (also called API key)
Request version (so the brokers can handle clients of different versions and respond accordingly)
Correlation ID: a number that uniquely identifies the request and also appears in the response and in the error logs (the ID is used for troubleshooting)
Client ID: used to identify the application that sent the request
由于Client并不知道要向哪个partition发消息,所以需要metadata request,然后broker返回topic,partition以及leader的信息。
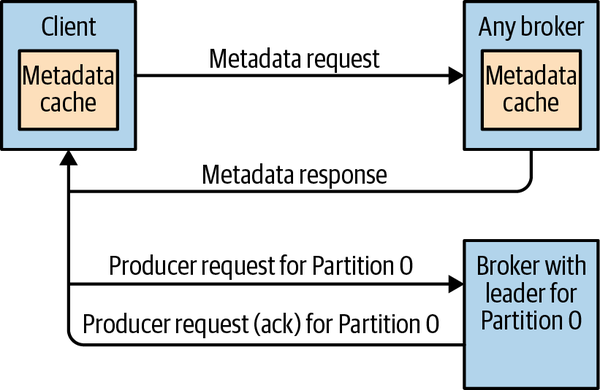
Produce request
Acks=<0,1,all>
不等待,只等待leader,等待所有replica sync
Fetch request
zero-copy
区别:
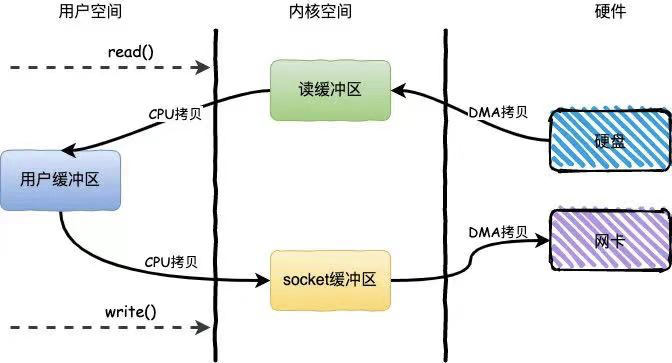
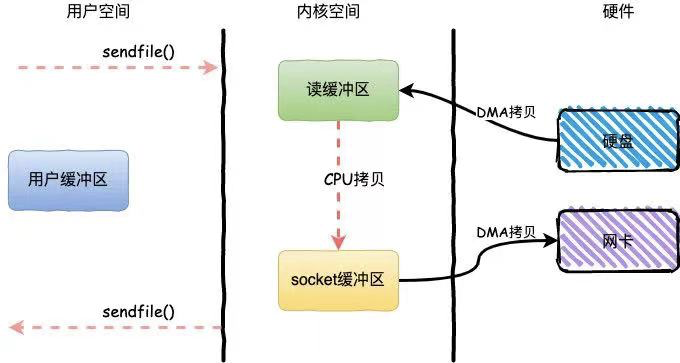
boundary
Lower boundary: Only return results once you have at least 10K bytes to send me
Upper boundary: Chunk
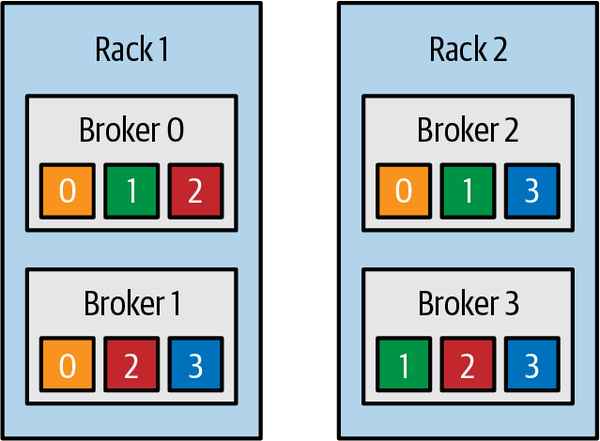
Partition Allocation
- 在Broker中平均分配
- 每个Partition的各个replica在不同broker中
- 机柜数据(0.10.0版本之后支持)
File
分段,比如1G或者一周的数据
删除时不能删除active segment
Indexes
每个partition都有一个index,对offset和文件位置作映射
Compact
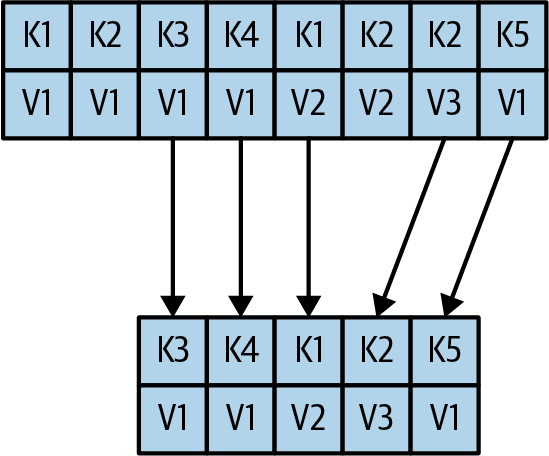
Producers Retry
message will be stored at least once, but not exactly once.
当然,也可以配置enable.idempotence,让broker跳过重复的消息。
Producer需要能够handle Non-retriable errors
Consumer
从Partition fetch一个batch,检查最后的offset,然后发出新的request 从最后的offset开始申请batch。
由于consumer可能会出错,或者停止,需要有一种手段来恢复到上一次consume的offset。这就需要consumer去commit offset。
对于每一个Partition,consumer都会存储当前的位置。当consumer确认收到并且处理完message后,才会向kafka commit offset。
Writing
timing配置
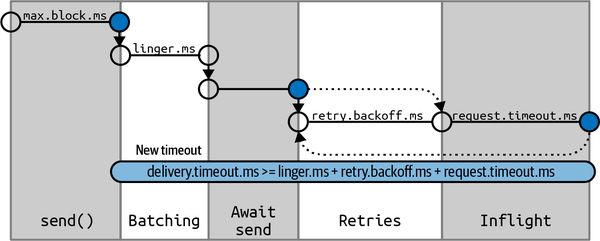
max.block.ms
producer调用send()之后,由于send buffer满了,或者metadata取不到,这时设置一个超时抛异常。
delivery.timeout.ms
request.timeout.ms
这个很好理解,就是请求发出去了但是server无应答,超时抛异常。
retry.backoff.ms
默认每隔100ms进行一次retry,但是通过这个参数可以进行调整。
linger.ms
producer会在两种情况下发送batch:
batch已经写满了消息
消息没写满,但是达到了linger.ms设置的等待时长
batch.size
Batch在内存中的字节长度
max.in.flight.requests.per.connection
在未收到response的情况下,最多发多少个请求。这个参数可以控制吞吐量,默认是5
in flight request如果大于1,那么有可能出现第一个batch失败,第二个成功的情况。
对于一些比如银行等业务,这个是不可接受的。但是小于2又会有性能问题。
enable.idempotence=true
message ordering <= 5时能够保证消息的顺序。
Quotas
quota.producer.default=2M
设置producer/consumer/request的 rate limit
但这个选项可能会导致消息囤积在producer的缓冲区,导致存储溢出
Reading
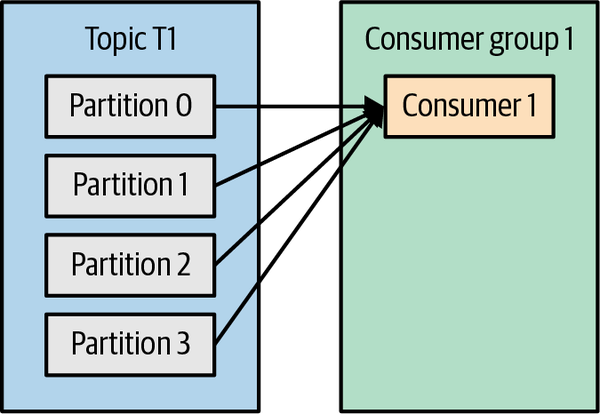
如果一个Consumer group里只有一个consumer,它会接收到所有Partition的消息。
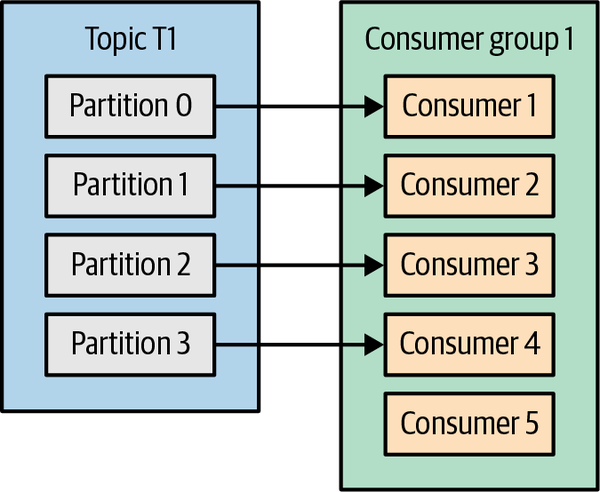
如果一个Consumer group里的consumer数量大于partition数量,有的consumer就接收不到消息了。
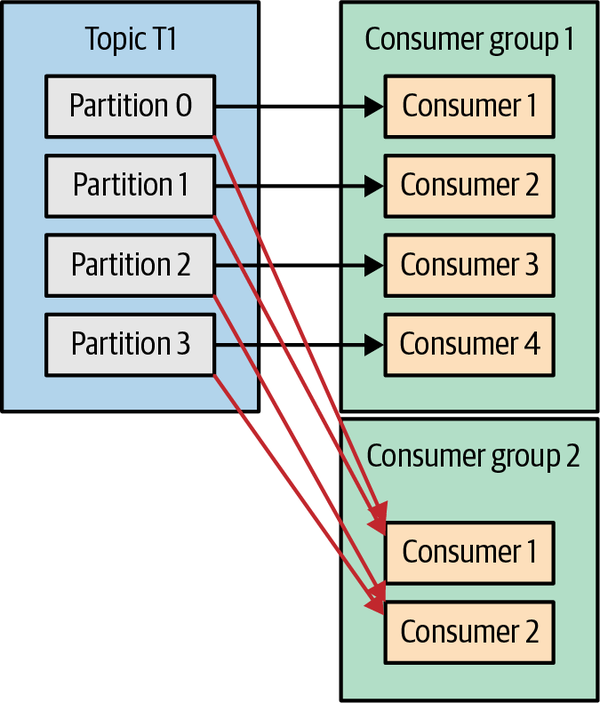
如果存在多个Consumer group,多个group之间是互相独立的。
Rebalance
将partition的ownership从一个consumer转移到另一个consumer,称为rebalance.
Eager rebalance
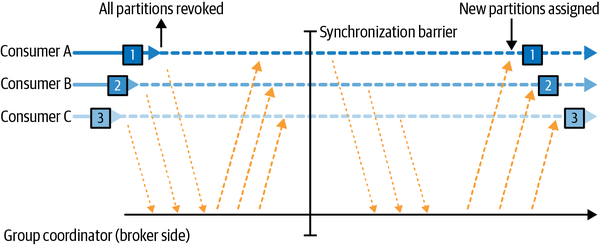
所有consumer暂停消费消息,放弃ownership,重新加入consumer group,等待broker重新分配ownership。
Cooperative rebalance(incremental rebalance)
Consumer group leader会通知其他consumer,哪些partition会被重新安排。own这些Partiton的consumer会停止消费这些partition的消息,然后consumer group leader将这些partition重新分配给目标consumer。
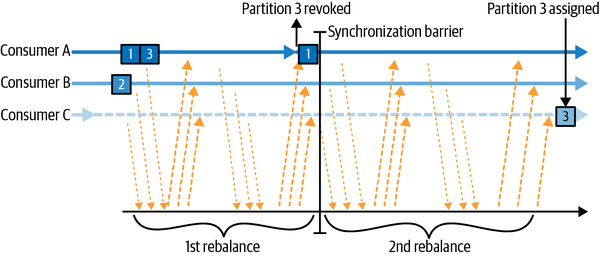
通过发送心跳包来确认consumer在线。
第一个加入Consumer group的成为group leader。
Static group membership
consumer也可以配置为静态的成员,这样当consumer断开连接后,它的partition不会被rearrange,而是等待它上线后恢复消费。
max.poll.interval.ms
尽管kafka通过background thread心跳包来确认consumer是否在线,但是在线并不代表它能够正常处理消息。
可以通过这个值来控制,如果client超过这个时间还没有发送第二次poll(),那么认为它的线程已经dead了。
默认是5分钟
auto.offset.reset
有latest和earliest两种,控制没有offset时是读取最新消息还是全量消息。
partition.assignment.strategy
Range
partition除以consumer count后,得到连续的编号范围,分配给consumer。
RoundRobin
把所有的partition one-by-one分配给consumers
Sticky
比RoundRobin更加平衡,在Reassign的时候减少了Rebalance的次数
Cooperative Sticky
支持Cooperative Rebalance
offsets.retention.minutes
Group里的消息被消费完了,默认保留7天,然后offset会清零,consumer group会和新加入的一样。
Offsets
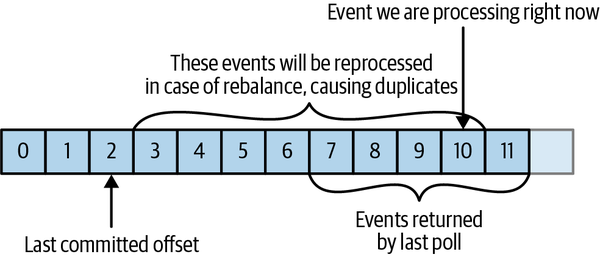
如上图,最坏的情况:如果BatchSize=5,上一个Batch处理完了,收到下一个Batch。但是Commit Offset=7没有发出去,然后处理到10的时候consumer挂了。这个时候,下一个接替的consumer会从2开始处理,导致从3~10这几个都被重复处理了。
解决办法就是manual commit offset,调用API处理完一条消息后就commit。
commitAsync没有retry,commitSync有retry。
当然,增加Specified commit会减少出错时重复处理的消息数量,但也会降低Throughput。
atomic multipartition writes
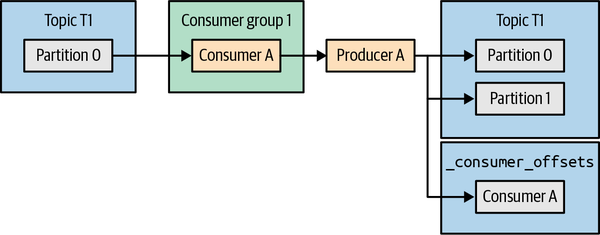
Consume,Process,Produce三步形成一个原子操作,就是让Produce时同时更新数据和Offset,要么都无法更新要么都可以更新。
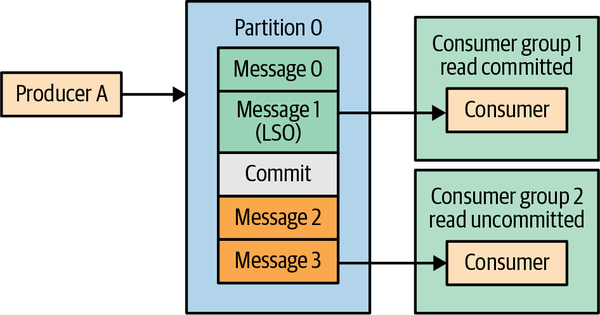
Last Stable Offset, or LSO
安装
Mac
安装openjdk
brew install openjdk
然后开启zookeeper
zookeeper-server-start /opt/homebrew/Cellar/kafka/3.2.0/libexec/config/zookeeper.properties
开启kafka
Enable JMX
ITOM Practitioner Portal (microfocus.com)
env JMX_PORT=<portnumber> kafka-server-start /opt/homebrew/Cellar/kafka/3.2.0/libexec/config/server.properties
创建topic
kafka-topics --bootstrap-server localhost:9092 --create --replication-factor 1 --partitions 1 --topic test
输出: Created topic test.
(base) ➜ ~ kafka-topics --bootstrap-server localhost:9092 --describe --topic test
Topic: test TopicId: cqJ9A01WRpOhwcD1sBLKTA PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
(base) ➜ ~
测试Consumer 和 Producer
(base) ➜ ~ kafka-console-producer --bootstrap-server localhost:9092 --topic test
>Hello Kafka
>Bye
>^C%
(base) ➜ ~ kafka-console-consumer --bootstrap-server localhost:9092 --topic test
^CProcessed a total of 0 messages
(base) ➜ ~ kafka-console-consumer --bootstrap-server localhost:9092 --topic test --from-beginning
Hello Kafka
Bye
^CProcessed a total of 2 messages
(base) ➜ ~ kafka-console-consumer --bootstrap-server localhost:9092 --topic test --from-beginning
Hello Kafka
Bye
^CProcessed a total of 2 messages
(base) ➜ ~
这里可以用zkcli看到,kafka已经在更新zookeeper的状态:
[zk: localhost:2181(CONNECTED) 2] ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
[zk: localhost:2181(CONNECTED) 3] ls /brokers
[ids, seqid, topics]
[zk: localhost:2181(CONNECTED) 4] ls /brokers/topics
[__consumer_offsets, test]
[zk: localhost:2181(CONNECTED) 5] ls /brokers/topics/test
[partitions]
[zk: localhost:2181(CONNECTED) 6] ls /brokers/topics/test/partitions
[0]
[zk: localhost:2181(CONNECTED) 7] ls /brokers/topics/test/partitions/0
[state]
[zk: localhost:2181(CONNECTED) 8] ls /brokers/topics/test/partitions/0/state
[]
[zk: localhost:2181(CONNECTED) 9] ls /brokers/topics/__consumer_offsets
[partitions]
[zk: localhost:2181(CONNECTED) 10] ls /brokers/topics/__consumer_offsets/partitions
[0, 1, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 2, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 3, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 4, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 5, 6, 7, 8, 9]
我们可以用cmak工具来看:
下载下来后,修改application.conf文件
cmak.zkhosts="0.0.0.0:2181"
然后启动,注意不要用jdk16以上的版本,加载css会报错,应该是个bug
bin/cmak -java-home /opt/homebrew/opt/openjdk@11/
然后访问localhost:9000
添加cluster, zk 设置为localhost:9000
可以看到topics,brokers
点进topics
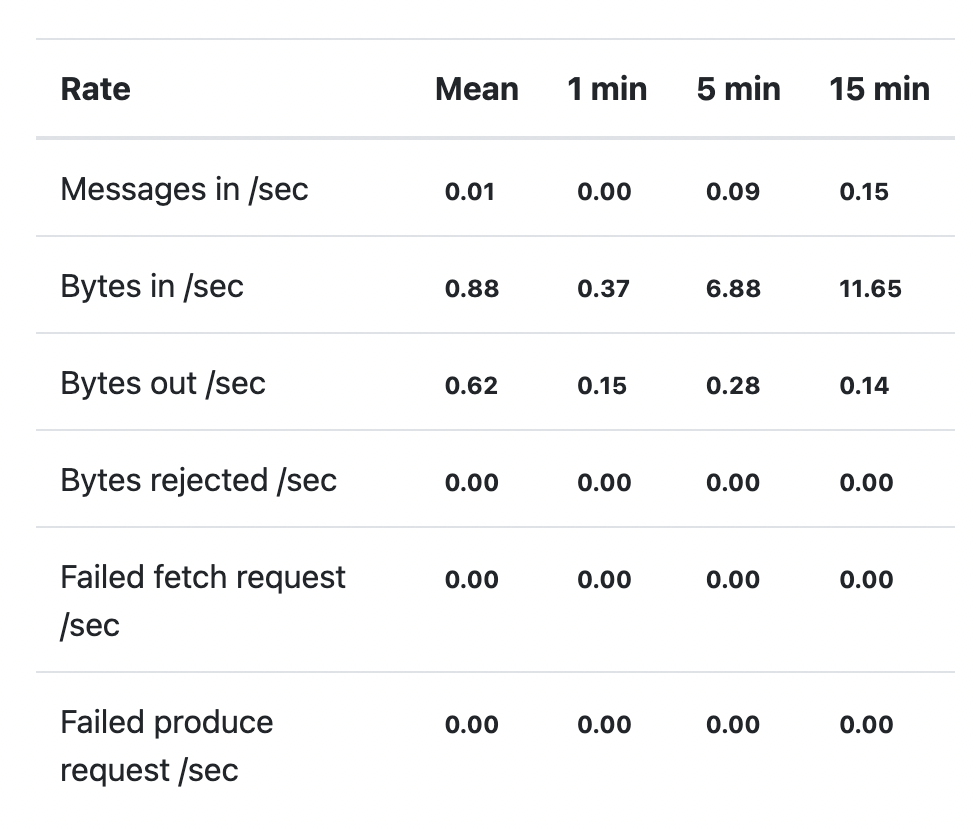
如果enable了JMX,我们就可以看到metrics了。
比如起一个console,作为consumer,一个作为producer
➜ ~ kafka-console-consumer --bootstrap-server localhost:9092 --topic test
~ kafka-console-producer --bootstrap-server localhost:9092 --topic test
>hello
>i'm fine
发现consumer那边收到了消息:
➜ ~ kafka-console-consumer --bootstrap-server localhost:9092 --topic test
hello
i'm fine
然后回到CMAK,刷新,发现metrics有变化